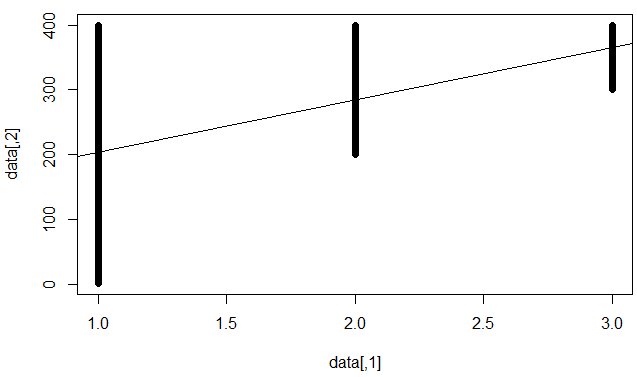
Det betyder "irreducible error is high", dvs. det bästa vi kan göra (med linjär modell) är begränsat. Till exempel följande datamängd:
data = rbind (
cbind (1,1: 400),
cbind (2200: 400),
cbind (3,300: 400))
plot (data)
Obs! Tricket i den här datamängden är att med ett $ x $ -värde finns det för många olika $ y $ -värden, att vi inte kan göra en bra förutsägelse för att tillfredsställa dem alla. Samtidigt finns det "starka" linjära korrelationer mellan $ x $ och $ y $. Om vi passar en linjär modell får vi betydande koefficienter, men låga R kvadrat.
fit = lm (data [, 2] ~ data [, 1])
sammanfattning (passform)
abline (passform)
Ring upp:
lm (formel = data [, 2] ~ data [, 1])
Rester:
Min 1Q Median 3Q Max
-203,331 -59,647 -1,252 68,103 195,669
Koefficienter:
Uppskatta Std. Fel t värde Pr (> | t |)
(Avlyssning) 123,910 8,428 14,70 <2e-16 ***
data [, 1] 80.421 4.858 16.56 <2e-16 ***
---
Signif. koder: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 '' 1
Restfel: 93,9 på 700 frihetsgrader
Multipel R-kvadrat: 0.2814, Justerad R-kvadrat: 0.2804
F-statistik: 274,1 på 1 och 700 DF, p-värde: < 2.2e-16