Ett vanligt problem som resulterar i överanpassning i verkliga livet är att vi förutom termer för en korrekt specificerad modell kan ha lagt till något främmande: irrelevanta krafter (eller andra transformationer) av de korrekta termerna, irrelevanta variabler eller irrelevanta interaktioner.
Detta händer i multipel regression om du lägger till en variabel som inte ska visas i den korrekt angivna modellen men inte vill släppa den eftersom du är rädd för att inducera utelämnad variabel bias. Naturligtvis har du inget sätt att veta att du felaktigt har inkluderat det, eftersom du inte kan se hela befolkningen, bara ditt urval, så du kan inte veta säkert vad den korrekta specifikationen är. (Som @Scortchi påpekar i kommentarerna kanske det inte finns något som "den korrekta" modellspecifikationen - i den meningen är målet med modellering att hitta en "tillräckligt bra" specifikation. För att undvika överanpassning innebär att man undviker en modellkomplexitet större än vad som kan upprätthållas av tillgängliga data.) Om du vill ha ett exempel på övermontering i verkligheten händer detta varje gång du kastar alla potentiella prediktorer i en regressionsmodell, om någon av dem faktiskt skulle har inget samband med svaret när andras effekter har delats ut.
Med denna typ av överanpassning är den goda nyheten att införandet av dessa irrelevanta termer inte introducerar förspänningar för dina uppskattare, och i mycket stora prover bör koefficienterna för de irrelevanta termerna vara nära noll. Men det finns också dåliga nyheter: Eftersom den begränsade informationen från ditt prov nu används för att uppskatta fler parametrar kan den bara göra det med mindre precision - så standardfelen på de verkligt relevanta villkoren ökar. Det betyder också att de sannolikt kommer att vara längre från de sanna värdena än uppskattningar från en korrekt specificerad regression, vilket i sin tur innebär att om nya värden för dina förklarande variabler ges kommer förutsägelserna från den överanpassade modellen att vara mindre exakta den korrekt angivna modellen.
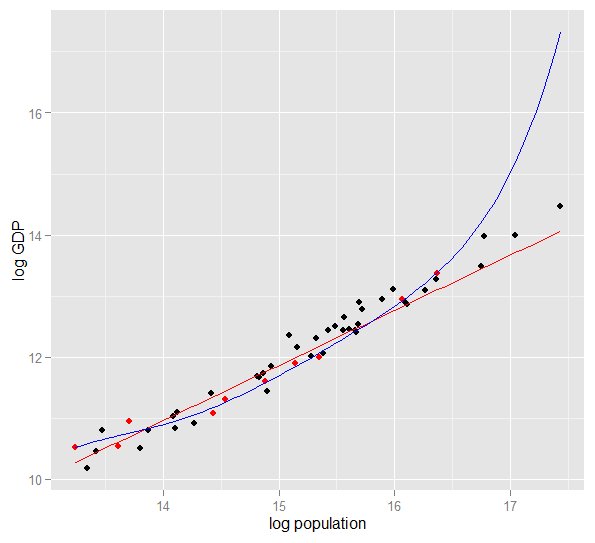
Här är ett diagram över logg-BNP mot logpopulation för 50 amerikanska stater 2010. Ett slumpmässigt urval på 10 stater valdes (markerat med rött) och för det provet passar vi ett enkelt linjär modell och en polynom av grad 5. För samplingspunkterna har polynom extra frihetsgrader som låter den "vrida sig" närmare de observerade data än den raka linjen kan. Men de 50 staterna som helhet följer ett nästan linjärt förhållande, så den prediktiva prestandan hos polynommodellen på de 40 punkterna utanför provet är mycket dålig jämfört med den mindre komplexa modellen, särskilt vid extrapolering. Polynomet passade effektivt till en del av den slumpmässiga strukturen (buller) i provet, vilket inte generaliserades för den bredare befolkningen. Det var särskilt dåligt vid extrapolering utanför provets observerade intervall. (Kod plus data för denna plot finns längst ner i denna version av detta svar.)
Liknande problem påverkar regression mot flera prediktorer. För att titta på några faktiska data är det enklare med simulering snarare än verkliga prover eftersom du på så sätt styr datagenereringsprocessen (effektivt får du se "befolkningen" och det verkliga förhållandet). I denna R -kod är den sanna modellen $ y_i = 2x_ {1, i} + 5 + \ epsilon_i $ men data tillhandahålls också om irrelevanta variabler $ x_2 $ och $ x_3 $. Jag har utformat simuleringen så att prediktorvariablerna är korrelerade, vilket skulle vara en vanlig förekomst i verkliga data. Vi passar modeller som är korrekt specificerade och överanpassade (inkluderar de irrelevanta prediktorerna och deras interaktioner) på en del av den genererade datan, och jämför sedan prediktiv prestanda i en uppehållssats. Prediktornas multikollinearitet gör livet ännu svårare för den överanpassade modellen, eftersom det blir svårare för den att plocka isär effekterna av $ x_1 $, $ x_2 $ och $ x_3 $, men notera att detta inte påverkar någon av koefficientuppskattarna .
kräver (MASS) # för multivariat normal simulering nsample <- 25 #sample to regress nholdout <- 1e6 #to check model predictionsSigma <- matrix (c (1, 0.5, 0.4, 0.5 , 1, 0,3, 0,4, 0,3, 1), nrow = 3) df <- as.data.frame (mvrnorm (n = (nsample + nholdout), mu = c (5,5,5), Sigma = Sigma) ) kolonnamn (df) <- c ("x1", "x2", "x3") df $ y <- 5 + 2 * df $ x1 + rnorm (n = nrow (df)) #y = 5 + * x1 + eholdout.df <- df [1: nholdout,] regress.df <- df [(nholdout + 1) :( nholdout + nsample),] overfit.lm <- lm (y ~ x1 * x2 * x3, regress. df) correctspec.lm <- lm (y ~ x1, regress.df) sammanfattning (overfit.lm) sammanfattning (correctspec.lm) holdout.df $ overfitPred <- predict.lm (overfit.lm, newdat a = holdout.df) holdout.df $ correctSpecPred <- förutsäga.lm (korrigerarpec.lm, newdata = holdout.df) med (holdout.df, sum ((y - overfitPred) ^ 2)) #SSEwith (holdout.df , sum ((y - correctSpecPred) ^ 2)) kräver (ggplot2)
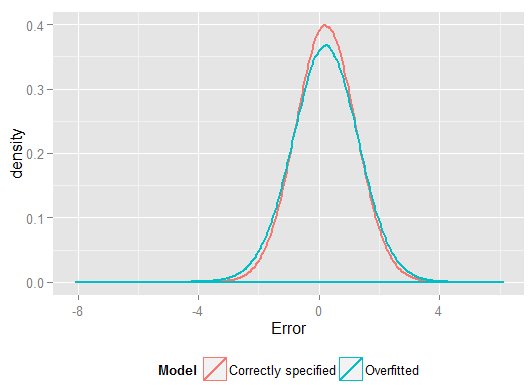
error.df <- data.frame (Model = rep (c ("Overfitted", "Correctly specified"), each = nholdout), Error = with (holdout.df, c (y - overfitPred, y - correctSpecPred))) ggplot (error.df, aes (x = Error, color = Model)) + geom_density (size = 1) + theme (legend.position = "bottom")
Här är mina resultat från en körning, men det är bäst att köra simuleringen flera gånger för att se effekten av olika genererade prover.
>-sammanfattning (overfit.lm) Ring: lm (formel = y ~ x1 * x2 * x3, data = regress.df) Rester: Min 1Q Median 3Q Max -2,22294 -0,63142 -0,09491 0,51983 2,24193 Koefficienter: Uppskattning Std. Fel t värde Pr (> | t |) (Avlyssning) 18.85992 65.00775 0.290 0.775x1 -2.40912 11.90433 -0.202 0.842x2 -2.13777 12.48892 -0.171 0.866x3 -1.13941 12.94670 -0.088 0.931x1: x2 0.78280 2.25867 0.347 0.73 0.73 0,232 0,819x2: x3 0,08019 2,49028 0,032 0,975x1: x2: x3 -0,08584 0,43891 -0,196 0,847 Restfel: 1,101 på 17 frihetsgrader Flera R-kvadrat: 0,8297, Justerad R-kvadrat: 0,7596 F-statistik: 11,84 på 7 och 17 DF, p-värde: 1.942e-05
Dessa koefficientuppskattningar för den överanpassade modellen är fruktansvärda - bör vara cirka 5 för avlyssningen, 2 för $ x_1 $ och 0 för resten . Men standardfelen är också stora. De korrekta värdena för dessa parametrar ligger väl inom 95% konfidensintervall i varje fall. $ R ^ 2 $ är 0,8297 vilket föreslår en rimlig passform.
>-sammanfattning (korrigerarpec.lm) Ring: lm (formel = y ~ x1, data = regress.df) Rest: Min 1Q Median 3Q Max -2.4951 -0.4112 -0.2000 0.7876 2.1706 Koefficienter: Uppskattning Std. Fel t värde Pr (> | t |) (Avlyssning) 4,77844 1,1272 4,244 0,000306 *** x1 1,9974 0,2108 9,476 2,09e-09 *** ---
Signif. koder: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 '' 1 Restfel kvarvarande: 1,036 vid 23 frihetsgrader Flera R-kvadrat: 0,7961, Justerat R-kvadrat: 0,7872 F-statistik : 89.8 på 1 och 23 DF, p-värde: 2.089e-09
Koefficientuppskattningarna är mycket bättre för den korrekt angivna modellen. Men notera att $ R ^ 2 $ är lägre, vid 0,7961, eftersom den mindre komplexa modellen har mindre flexibilitet för att passa de observerade svaren. $ R ^ 2 $ är farligare än användbart i det här fallet!
> with (holdout.df, sum ((y - overfitPred) ^ 2)) # SSE [1] 1271557> med (holdout.df, sum ((y - correctSpecPred) ^ 2)) [1] 1052217
Ju högre $ R ^ 2 $ på provet vi minskade på visade hur den överutrustade modellen producerade förutsägelser, $ \ hat {y} $, som var närmare den observerade $ y $ än den korrekt angivna modellen kunde. Men det beror på att det var överanpassat till dessa data (och hade mer frihetsgrader att göra så än den korrekt angivna modellen gjorde, så det kunde ge en "bättre" passform). Titta på summan av kvadrerade fel för förutsägelser på håll-set, som vi inte använde för att uppskatta regressionskoefficienterna från, och vi kan se hur mycket värre den överutrustade modellen har utfört. I verkligheten är den korrekt specificerade modellen den som ger de bästa förutsägelserna. Vi bör inte basera vår bedömning av den prediktiva prestationen på resultaten från den uppsättning data vi använde för att uppskatta modellerna. Här är en densitetsdiagram över felen, med rätt modellspecifikation som ger fler fel nära 0:
Simuleringen representerar tydligt många relevanta verkliga situationer (tänk dig alla verkliga svar som beror på en enda prediktor och föreställ dig att inkludera externa "prediktorer" i modellen) men har fördelen att du kan spela med data -genereringsprocess, provstorlekar, typen av överanpassad modell och så vidare. Detta är det bästa sättet att undersöka effekterna av överanpassning eftersom för observerade data har du generellt inte tillgång till DGP, och det är fortfarande "riktiga" data i den meningen att du kan undersöka och använda den. Här är några värdefulla idéer som du bör experimentera med:
- Kör simuleringen flera gånger och se hur resultaten skiljer sig åt. Du hittar mer variation med små provstorlekar än stora.
- Prova att ändra provstorlekarna. Om den ökas till, säg n <- 1e6 , uppskattar den överutrustade modellen så småningom rimliga koefficienter (ca 5 för avlyssning, ca 2 för $ x_1 $, ca 0 för allt annat) och dess prediktiva prestanda som mätt med SSE spårar inte den rätt angivna modellen så illa. Omvänt, försök att montera ett mycket litet urval (kom ihåg att du måste lämna tillräckligt med frihetsgrader för att uppskatta alla koefficienter) och du kommer att se att den överutrustade modellen har skrämmande prestanda både för att uppskatta koefficienter och förutsäga för nya data. li>
- Försök att minska korrelationen mellan prediktorvariablerna genom att spela med de diagonala elementen i varianskovariansmatrisen Sigma . Kom bara ihåg att hålla det positivt halvt bestämt (som inkluderar att vara symmetrisk). Du bör hitta om du minskar multikollineariteten, den överanpassade modellen fungerar inte riktigt så illa. Men kom ihåg att korrelerade prediktorer förekommer i verkliga livet.
- Försök att experimentera med specifikationen för den överanpassade modellen. Vad händer om du tar med polynomiska termer?
- Vad händer om du simulerar data för en annan region av prediktorer, snarare än att ha deras medel runt 5? Om den korrekta datagenereringsprocessen för $ y $ fortfarande är df $ y <- 5 + 2 * df $ x1 + rnorm (n = nrow (df)) , se hur väl modellerna passar till ursprungliga data kan förutsäga att $ y $. Beroende på hur du genererar $ x_i $ -värdena kan det hända att extrapolering med den överanpassade modellen ger förutsägelser mycket sämre än den korrekt angivna modellen.
- Vad händer om du ändrar datagenereringsprocessen så att $ y $ nu, svagt, beror på $ x_2 $, $ x3 $ och kanske också interaktionerna? Detta kan vara ett mer realistiskt scenario som beror på $ x_1 $ ensam. Om du använder t.ex. df $ y <- 5 + 2 * df $ x1 + 0.1 * df $ x2 + 0.1 * df $ x3 + rnorm (n = nrow (df)) då är $ x_2 $ och $ x_3 $ "nästan irrelevant", men inte riktigt. (Observera att jag ritade alla $ x $ -variablerna från samma intervall, så det är vettigt att jämföra deras koefficienter så.) Då lider den enkla modellen med endast $ x_1 $ utelämnad variabel bias, men sedan $ x_2 $ och $ x_3 $ är inte särskilt viktiga, det här är inte för allvarligt. På ett litet prov, t.ex.
nsample <- 25 , hela modellen är fortfarande överanpassad, trots att den är en bättre representation av den underliggande befolkningen, och vid upprepade simuleringar är dess prediktiva prestanda på hållset fortfarande konsekvent sämre. Med sådana begränsade data är det viktigare att få en bra uppskattning av koefficienten på $ x_1 $ än att spendera information om lyxen att uppskatta de mindre viktiga koefficienterna. Eftersom effekterna av $ x_2 $ och $ x_3 $ är så svåra att urskilja i ett litet urval, använder hela modellen effektivt flexibiliteten från sina extra frihetsgrader för att "passa ljudet" och detta generaliserar dåligt. Men med nsample <- 1e6 kan det uppskatta de svagare effekterna ganska bra, och simuleringar visar att den komplexa modellen har prediktiv kraft som överträffar den enkla. Detta visar hur "överanpassning" är en fråga om både modellkomplexitet och tillgänglig data.