Varför kvadrera skillnaden istället för att ta det absoluta värdet i standardavvikelse?
Vi kvadrerar skillnaden mellan x och medelvärdet eftersom det euklidiska avståndet är proportionellt mot kvadratroten av frihetsgraderna (antal x i ett populationsmått) är det bästa måttet på dispersion.
Det vill säga när x-talet har noll betyder $ \ mu = 0 $ :
$$
\ sigma = \ sqrt {\ frac {\ displaystyle \ sum_ {i = 1} ^ {n} (x_i - \ mu) ^ 2} {n}} = \ frac {\ sqrt {\ displaystyle \ sum_ {i = 1 } ^ {n} (x_i) ^ 2}} {\ sqrt {n}} = \ frac {distans} {\ sqrt {n}}
$$
Kvadratroten av kvadratsumman är det flerdimensionella avståndet från medelvärdet till punkten i högdimensionellt utrymme som anges av varje datapunkt.
Beräkna avstånd
Vad är avståndet från punkt 0 till punkt 5?
- $ 5-0 = 5 $ ,
- $ | 0-5 | = 5 $ och
- $ \ sqrt {5 ^ 2} = 5 $
Okej, det är trivialt eftersom det är en enda dimension.
Vad sägs om avståndet från punkt (0, 0) till punkt (3, 4)?
Om vi bara kan gå i en dimension åt gången (som i stadsblock) så lägger vi bara till siffrorna. (Detta kallas ibland Manhattan-avståndet).
Men vad sägs om att gå i två dimensioner samtidigt? Sedan (av Pythagoras sats som vi alla lärde oss på gymnasiet), kvadrerar vi avståndet i varje dimension, summerar rutorna och tar sedan kvadratroten för att hitta avståndet från ursprunget till punkten.
$$
\ sqrt {3 ^ 2 + 4 ^ 2} = \ sqrt {25} = 5
$$
Visuellt (se markdown-källan för svaret för koden som ska genereras):
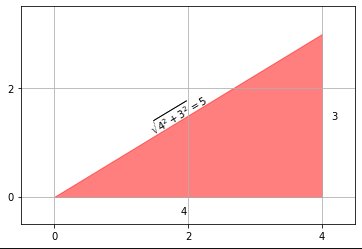
Beräkning av avstånd i högre dimensioner
Låt oss nu överväga det tredimensionella fallet, till exempel vad sägs om avståndet från punkt (0, 0, 0) till punkt (2, 2, 1)?
Det här är bara
$$
\ sqrt {\ sqrt {2 ^ 2 + 2 ^ 2} ^ 2 + 1 ^ 2} =
\ sqrt {2 ^ 2 + 2 ^ 2 + 1 ^ 2} = \ sqrt9 = 3
$$
eftersom avståndet för de första två x: erna utgör benet för att beräkna det totala avståndet med det sista x.
$$
\ sqrt {\ sqrt {x_1 ^ 2 + x_2 ^ 2} ^ 2 + x_3 ^ 2} = \ sqrt {x_1 ^ 2 + x_2 ^ 2 + x_3 ^ 2}
$$
Visas visuellt:
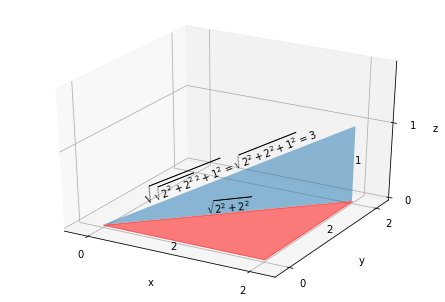
Vi kan fortsätta att utöka regeln om att kvadrera varje dimensions avstånd,
detta generaliserar till vad vi kallar ett euklidiskt avstånd, för ortogonala mätningar i hyperdimensionellt utrymme, som så:
$$
avstånd = \ sqrt {\ sum \ nolimits_ {i = 1} ^ n {x_i ^ 2}}
$$
och så är summan av ortogonala kvadrater kvadratavståndet:
$$
avstånd ^ 2 = \ sum_ {i = 1} ^ n {x_i ^ 2}
$$
Vad gör en mätning ortogonal (eller i rät vinkel) mot en annan? Villkoret är att det inte finns något samband mellan de två mätningarna. Vi skulle leta efter att dessa mätningar är oberoende och individuellt fördelade , ( i.i.d. ).
Varians
Kom ihåg formeln för populationsvarians (från vilken vi får standardavvikelsen):
$$
\ sigma ^ 2 = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} (x_i - \ mu) ^ 2} {n}
$$
Om vi redan har centrerat data vid 0 genom att subtrahera medelvärdet har vi:
$$
\ sigma ^ 2 = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} (x_i) ^ 2} {n}
$$
Så vi ser att variansen bara är kvadratavståndet eller $ distance ^ 2 $ (se ovan), dividerat med antalet av frihetsgrader (antalet dimensioner där variablerna är fria att variera). Detta är också det genomsnittliga bidraget till $ distance ^ 2 $ per mätning. "Genomsnittlig kvadratisk varians" skulle också vara en lämplig term.
Standardavvikelse
Sedan har vi standardavvikelsen, som bara är kvadratroten av variansen:
$$
\ sigma = \ sqrt {\ frac {\ displaystyle \ sum_ {i = 1} ^ {n} (x_i - \ mu) ^ 2} {n}}
$$
Vilket motsvarar avståndet , dividerat med kvadratroten av frihetsgraderna:
$$
\ sigma = \ frac {\ sqrt {\ displaystyle \ sum_ {i = 1} ^ {n} (x_i) ^ 2}} {\ sqrt {n}}
$$
Genomsnittlig absolut avvikelse
Mean Absolute Deviation (MAD), är ett mått på dispersion som använder Manhattan-avståndet, eller summan av absoluta värden för skillnaderna från medelvärdet.
$$
MAD = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} | x_i - \ mu |} {n}
$$
Återigen, förutsatt att data är centrerade (medelvärdet subtraherat) har vi Manhattan-avståndet dividerat med antalet mätningar:
$$
MAD = \ frac {\ displaystyle \ sum_ {i = 1} ^ {n} | x_i |} {n}
$$
Diskussion
- Den genomsnittliga absoluta avvikelsen är ungefär .8 gånger ( faktiskt $ \ sqrt {2 / \ pi} $ ) storleken på standardavvikelse för en normalt distribuerad dataset.
- Oavsett fördelning är den genomsnittliga absoluta avvikelsen mindre än eller lika med standardavvikelsen. MAD underskattar spridningen av en datamängd med extrema värden i förhållande till standardavvikelsen.
- Genomsnittlig absolut avvikelse är mer robust för avvikare (dvs. avvikare har inte lika stor effekt på statistiken som för standardavvikelse.
- Geometriskt sett, om mätningarna inte är ortogonala mot varandra (iid) - om de till exempel var positivt korrelerade, skulle medelavvikelsen vara bättre beskrivande statistik än standardavvikelsen, som förlitar sig på euklidiskt avstånd (även om detta är anses vanligtvis vara bra).
Denna tabell återspeglar ovanstående information på ett mer kortfattat sätt:
$$
\ begin {array} {lll}
& MAD & \ sigma \\ \ hline
storlek & \ le \ sigma & \ ge MAD \\
storlek, \ sim N & .8 \ gånger \ sigma & 1,25 \ gånger MAD \\
avvikare & robust & påverkad \\
inte \ i.i.d. & robust & ok
\ end {array}
$$
Kommentarer:
Har du en referens för "genomsnittlig absolut avvikelse är ungefär .8 gånger storleken på standardavvikelsen för ett normalt distribuerat dataset"? Simuleringarna jag kör visar att detta är felaktigt.
Här är tio simuleringar av en miljon prover från standardnormalfördelningen:
>>> från numpy.random import standard_normal
>>> från numpy import medelvärde, absolut
>>> för _ inom intervallet (10):
... array = standard_normal (1_000_000)
... skriv ut (numpy.std (array), medelvärde (absolut (array - medelvärde (array))))
...
0,9999303226807994 0,7980634269273035
1,001126461808081 0,7985832977798981
0,9994247275533893 0,7980171649802613
0,9994142105335478 0,7972367136320848
1.0001188211817726 0.798021564315937
1.000442654481297 0.7981845236910842
1.0001537518728232 0.7975554993742403
1.0002838369191982 0.798143108250063
0,9999060114455384 0,797895284109523
1.0004871065680165 0.798726062813422
Slutsats
Vi föredrar kvadratiska skillnader när vi beräknar ett mått på dispersion eftersom vi kan utnyttja det euklidiska avståndet, vilket ger oss en bättre diskriptiv statistik över dispersionen. När det finns mer relativt extrema värden står det euklidiska avståndet för det i statistiken, medan Manhattan-avståndet ger varje mätning lika vikt.