Din oro är precis den oro som ligger till grund för en stor del av den nuvarande vetenskapliga diskussionen om reproducerbarhet. Det verkliga läget är dock lite mer komplicerat än du föreslår.
Låt oss först skapa en terminologi. Nullhypotes-betydelsestest kan förstås som ett signaldetekteringsproblem - nollhypotesen är antingen sant eller falskt och du kan antingen välja att avvisa eller behålla den. Kombinationen av två beslut och två möjliga "sanna" situationer resulterar i följande tabell, som de flesta människor ser någon gång när de först lär sig statistik:
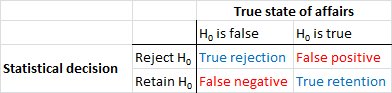
Forskare som använder nollhypotes-betydelsestest försöker maximera antalet korrekta beslut (visas i blått) och minimera antalet felaktiga beslut (visas i rött). Arbetande forskare försöker också publicera sina resultat så att de kan få jobb och utveckla sin karriär.
Naturligtvis, kom ihåg att, som många andra svarare redan har nämnt, är nollhypotesen inte vald vid slumpmässigt - istället väljs det vanligtvis specifikt för att forskaren, baserat på tidigare teori, anser att den är falsk . Tyvärr är det svårt att kvantifiera hur många gånger forskare har rätt i sina förutsägelser, men kom ihåg att när forskare har att göra med kolumnen "$ H_0 $ är falsk" borde de vara oroliga för falska negativa snarare än falska positiva.
Du verkar dock vara bekymrad över falska positiva, så låt oss fokusera på kolumnen "$ H_0 $ är sant". I denna situation, vad är sannolikheten för att en forskare publicerar ett falskt resultat?
Publikationsbias
Så länge som sannolikheten för publicering inte beror på om resultatet är "signifikant" är sannolikheten exakt $ \ alpha $ - .05, och ibland lägre beroende på fältet. Problemet är att det finns goda bevis för att sannolikheten för publicering inte beror på om resultatet är signifikant (se till exempel Stern & Simes, 1997; Dwan et al., 2008), antingen för att forskare bara lämnar signifikanta resultat för publicering (det så kallade fil-lådproblemet; Rosenthal, 1979) eller för att icke-signifikanta resultat lämnas in för publicering men gör det inte genom peer review.
Den allmänna frågan om sannolikheten för publicering beroende på den observerade $ p $ -värdet är vad som menas med publikationsbias . Om vi tar ett steg tillbaka och tänker på konsekvenserna av publikationsbias för en bredare forskningslitteratur, kommer en forskningslitteratur som påverkas av publikationsbias fortfarande att innehålla verkliga resultat - ibland den nollhypotes som en forskare hävdar att vara falsk kommer verkligen att vara falsk, och beroende på graden av publikationsfördomar, ibland kommer en forskare att korrekt hävda att en given nullhypotes är sant. Forskningslitteraturen kommer emellertid också att vara rörig av en alltför stor andel av falska positiva (dvs. studier där forskaren hävdar att nollhypotesen är falsk när den verkligen är sant).
Forskare frihetsgrader
Publikationsbias är inte det enda sättet att sannolikheten att publicera ett betydande resultat under nollhypotesen är större än $ \ alpha $. När de används felaktigt kan vissa områden med flexibilitet i utformningen av studier och analys av data, som ibland är märkta forskare grader av frihet ( Simmons, Nelson, & Simonsohn, 2011), öka frekvensen av falska positiva, även om det inte finns någon publikationsbias. Om vi till exempel antar att alla (eller vissa) forskare, när vi får ett icke-signifikant resultat, kommer att utesluta en avlägsen datapunkt om denna uteslutning kommer att ändra det icke-signifikanta resultatet till ett signifikant, kommer frekvensen av falska positiva att vara större än $ \ alpha $. Med tanke på närvaron av ett tillräckligt stort antal tvivelaktiga forskningsmetoder kan frekvensen av falska positiva gå så högt som .60 även om den nominella frekvensen sattes till 0,05 ( Simmons, Nelson, & Simonsohn, 2011).
Det är viktigt att notera att felaktig användning av forskares grader av frihet (som ibland kallas tvivelaktiga forskningsmetoder; Martinson, Anderson, & de Vries, 2005 ) är inte samma som att skapa data. I vissa fall är det rätta att utesluta avvikare, antingen på grund av att utrustningen misslyckas eller av någon annan anledning. Nyckelfrågan är att de beslut som fattas under analysen i närvaro av forskarnas frihetsgrader ofta beror på hur uppgifterna blir ( Gelman & Loken, 2014), även om forskarna i fråga är inte är medveten om detta faktum. Så länge forskare använder forskarnivåer av frihet (medvetet eller omedvetet) för att öka sannolikheten för ett signifikant resultat (kanske för att signifikanta resultat är mer "publicerbara"), kommer närvaron av forskargrader att överbefolka en forskningslitteratur med falska positiva effekter i på samma sätt som publikationsbias.
En viktig varning för ovanstående diskussion är att vetenskapliga artiklar (åtminstone inom psykologi, som är mitt område) sällan består av enstaka resultat. Mer vanligt är flera studier, var och en involverar flera tester - tonvikten ligger på att bygga ett större argument och utesluta alternativa förklaringar för det presenterade beviset. Den selektiva presentationen av resultat (eller närvaron av forskarens frihetsgrader) kan emellertid ge bias i en uppsättning resultat lika enkelt som ett enda resultat. Det finns bevis för att resultaten som presenteras i multistudier ofta är mycket renare och starkare än man kan förvänta sig även om alla förutsägelser i dessa studier var sanna ( Francis, 2013).
Slutsats>
I grund och botten håller jag med din intuition om att nollhypotesens betydelsestest kan gå fel. Jag skulle emellertid hävda att de verkliga synderna som producerar en hög grad av falska positiva är processer som publikationsbias och närvaron av forskargrader. Faktum är att många forskare är väl medvetna om dessa problem och att förbättra den vetenskapliga reproducerbarheten är ett mycket aktivt aktuellt diskussionsämne (t.ex. Nosek & Bar-Anan, 2012; Nosek, Spies, & Motyl , 2012). Så du är i gott sällskap med dina bekymmer, men jag tror också att det också finns skäl till viss försiktig optimism.
Referenser
Stern, JM, & Simes, RJ (1997). Publikationsbias: Bevis på försenad publicering i en kohortstudie av kliniska forskningsprojekt. BMJ, 315 (7109), 640–645. http://doi.org/10.1136/bmj.315.7109.640
Dwan, K., Altman, DG, Arnaiz, JA, Bloom, J., Chan, A ., Cronin, E., ... Williamson, PR (2008). Systematisk granskning av empiriska bevis för bias i studiepublikationer och resultatrapportering. PLoS ONE, 3 (8), e3081. http://doi.org/10.1371/journal.pone.0003081
Rosenthal, R. (1979). Fillådans problem och tolerans för nollresultat. Psychological Bulletin, 86 (3), 638–641. http://doi.org/10.1037/0033-2909.86.3.638
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). Falsk-positiv psykologi: Oupptäckt flexibilitet i datainsamling och analys gör det möjligt att presentera någonting så viktigt. Psykologisk vetenskap, 22 (11), 1359–1366. http://doi.org/10.1177/0956797611417632
Martinson, B. C., Anderson, M. S., & de Vries, R. (2005). Forskare beter sig dåligt. Natur, 435, 737–738. http://doi.org/10.1038/435737a
Gelman, A., & Loken, E. (2014). Den statistiska krisen inom vetenskapen. American Scientist, 102, 460-465.
Francis, G. (2013). Replikering, statistisk konsistens och publikationsbias. Journal of Mathematical Psychology, 57 (5), 153–169. http://doi.org/10.1016/j.jmp.2013.02.003
Nosek, B. A., & Bar-Anan, Y. (2012). Vetenskaplig utopi: I. Inledande vetenskaplig kommunikation. Psykologisk undersökning, 23 (3), 217–243. http://doi.org/10.1080/1047840X.2012.692215
Nosek, B. A., Spies, J. R., & Motyl, M. (2012). Vetenskaplig utopi: II. Omstruktureringsincitament och metoder för att främja sanning över publiceringsbarhet. Perspectives on Psychological Science, 7 (6), 615–631. http://doi.org/10.1177/1745691612459058