Varför den stora skillnaden
-
Om dina data normalt distribueras eller fördelas enhetligt, skulle jag tro att Spearmans och Pearsons korrelation borde vara ganska lika.
-
Om de ger väldigt olika resultat som i ditt fall (.65 kontra .30), är min gissning att du har snedställda data eller outliers, och att outliers leder till Pearson's korrelation att vara större än Spearmans korrelation . Det vill säga att mycket höga värden på X kan uppstå samtidigt med mycket höga värden på Y.
- @chl är spot on. Ditt första steg bör vara att titta på spridningsdiagrammet.
- I allmänhet är en så stor skillnad mellan Pearson och Spearman en röd flagga som tyder på att
- Pearson-korrelationen kanske inte är till nytta sammanfattning av sambandet mellan dina två variabler, eller
- du bör transformera en eller båda variablerna innan du använder Pearson's korrelation, eller
- du bör ta bort eller justera outliers innan du använder Pearson's korrelation.
Relaterade frågor
Se även dessa tidigare frågor om skillnader mellan Spearman och Pearsons korrelation:
Enkelt R-exempel
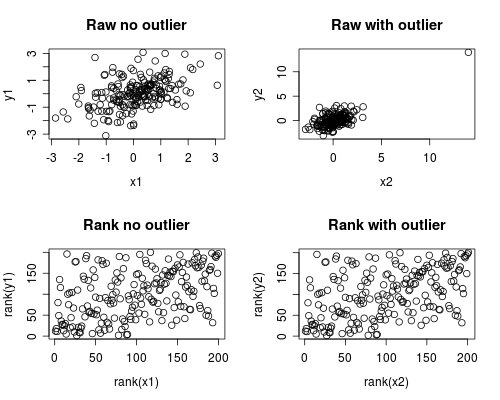
Följande är en enkel simulering av hur detta kan inträffa. Observera att fallet nedan involverar en enda outlier, men att du kan producera liknande effekter med flera avvikelser eller skev data.
# Set Seed of r andom number generatorset.seed (4444) # Generera slumpmässiga data # Skapa först några normalt distribuerade korrelerade datax1 <- rnorm (200) y1 <- rnorm (200) + .6 * x1 # För det andra, lägg till en större outlierx2 <- c ( x1, 14) y2 <- c (y1, 14) # Plotta båda datasetspar (mfrow = c (2,2)) plot (x1, y1, main = "Raw no outlier") plot (x2, y2, main = "Raw with outlier") plot (rank (x1), rank (y1), main = "Rank no outlier") plot (rank (x2), rank (y2), main = "Rank with outlier")
# Beräkna korrelationer på båda datamängderna (cor (x1, y1, metod = "pearson"), 2) runda (cor (x1, y1, metod = "spearman"), 2) runda (cor (x2, y2, metod = " pearson "), 2) rund (cor (x2, y2, metod =" spearman "), 2)
Vilket ger denna utdata
[1 ] 0.44 [1] 0.44 [1] 0.7 [1] 0.44
Korrelationsanalysen visar att Spearman och Pearson är ganska lika, och med den ganska extrema outlierna är korrelationen helt annorlunda.
Diagrammet nedan visar hur behandling av data som rangordningar tar bort det extrema inflytandet från outlier, vilket leder till att Spearman liknar både med och utan outlier medan Pearson är helt annorlunda när outlier läggs till .Detta belyser varför Spearman ofta kallas robust.